Response body processing
You can use the EdgeWorkers httpRequest() function to make an HTTPS request and retrieve the response body. Use httpRequest in your EdgeWorkers code to:
- Read data from services.
- Send data to services.
- Retrieve and then manipulate the response content.
To read an EdgeWorkers response body it can be buffered or streamed. This tutorial explains how to work with both buffered and streamed EdgeWorkers HTTPS responses. You'll also learn which approach is the best for your use case.
A buffered response reads the entire response body into a single JavaScript variable. An example of buffering in another context is when you download an entire video file and play it back from your computer.
A streamed response flows through the EdgeWorkers function reading individual parts of the response, one chunk at a time. An example of streaming in another context is when you watch live video content, the video is delivered to your device a small section of content at a time.
EdgeWorkers provides an html-rewriter module to use in your EdgeWorkers functions to consume and rewrite HTML documents. The html-rewriter module includes a built-in parser that emulates standard HTML parsing and DOM-construction.
1. Buffered responses
Buffered responses read the entire response body into a single JavaScript variable. This approach has advantages and disadvantages. The main advantage of using buffered responses is that they are easy to work with. Since the entire response body is in a variable you can:
- Work with the response as a single string using
httpResponse.text(). - Work with the response as a JavaScript object parsed from a JSON body using
httpResponse.json(). - Use the value in the string or object for further logic within the EdgeWorkers function.
When the response is available as a string it can also make further parsing easy. For example, you can use a JavaScript library such as xmldom, to parse a string containing XML to a JavaScript object.
The disadvantage of buffered responses is that EdgeWorkers must load the entire response into memory. Buffering a sizable response can consume most of the the allowed memory resources.
The code below finds all instances of "red" in the response and replaces them with "green".
import { httpRequest } from 'http-request';
import { createResponse } from 'create-response';
export async function responseProvider(request) {
var httpResponse = await httpRequest('https://www.example.com/content.html');
var bufferedBody = await httpResponse.text();
var modifiedBody = bufferedBody.replace("red", "green");
return createResponse(200, {}, modifiedBody);
}Use these guidelines to estimate the memory requirements to process the HTTP response.
- The
bufferedBodystring consumes one byte per character in the HTTP response body. - The
modifiedBodystring adds an additional one byte per character. As an example, a 128KB HTTP response results in the EdgeWorkers function consuming approximately 200KB of memory. - If any character in the response is not representable as a single-byte character, V8 represents the entire string with two bytes per character. This doubles the memory consumption estimate to ~400 KB.
2. Streamed responses
To process larger amounts of response data, EdgeWorkers provides the ability to stream response bodies from the httpRequest. A streamed response breaks the response into small chunks that the stream reads one chunk at a time. Processing data a single chunk at a time avoids having to load the entire response into memory. This helps you to stay below the EdgeWorkers memory limits for large responses.
For more information about processing streams, see the following resources.
- Streams API - Web APIs | MDN
- Google's Streams—The definitive guide
You can ignore the last section, "Useful streams available in the browser", but the remainder applies to streams in EdgeWorkers. - The streams supported in EdgeWorkers follow the WHATWG Streams Standard. This standard provides consistency with streams supported in browsers.
Node.js does not use the WHATWG streams standard. Libraries that rely on Node.js streams are not directly compatible with EdgeWorkers.
Producers and consumers
A producer writes data to a stream and a consumer reads data.
The EdgeWorkers platform acts a producer when:
- Calling
httpRequest(). - Writing the response content to a stream of bytes.
The EdgeWorkers platform acts as a consumer when:
- Calling
createResponse(). - Reading a stream of bytes and sending the response to the CDN proxy.
The EdgeWorkers code below acts as a consumer and a producer. It makes an httpRequest, creating a stream. The stream is then passed to the createResponse() function, effectively passing the stream to the end-client.

import { httpRequest } from 'http-request';
import { createResponse } from 'create-response';
export async function responseProvider(request) {
var httpResponse = await httpRequest('https://www.example.com/content.html');
var bodyStream = httpResponse.body;
return createResponse(200, {}, bodyStream);
}Transformers
To modify the content of a stream as it flows through the EdgeWorkers function, you can use a stream transformer. A transformer functions as a pair of streams, one writable stream and one readable stream. It consumes data that is written to the writable stream and produces data that can be consumed through the readable stream.
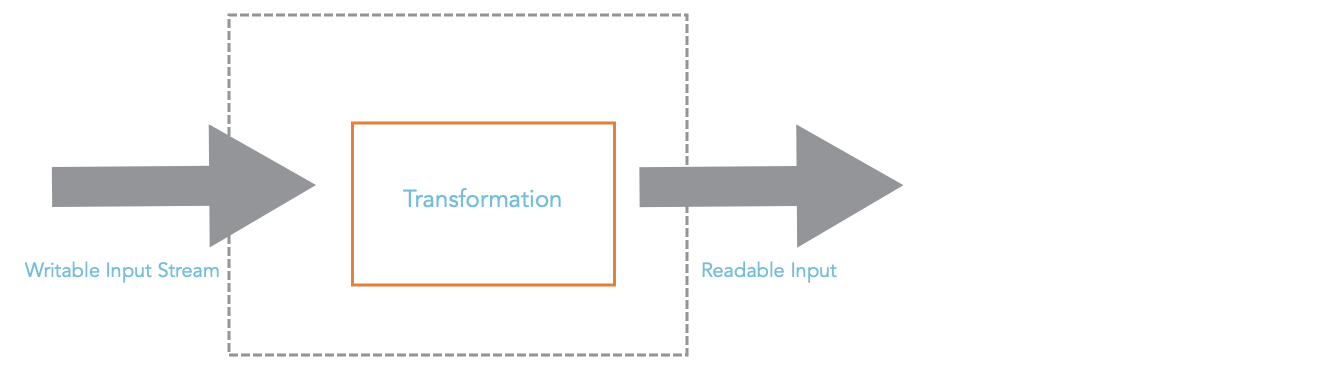
To demonstrate the transform stream, you can implement a find-replace within an EdgeWorkers function. This example uses a transform stream to find all instances of a specific substring and replaces them with a different string. However, EdgeWorkers httpRequest() and createResponse() don't work with streams of text, they work with streams of bytes.
To make find and replace easier, you can use the TextDecoderStream to transform the byte stream to a text stream and TextEncoderStream to transform a text stream to a byte stream. The EdgeWorkers text-encode-transform module includes both of these transformers. You can then create a new transformer, FindReplaceStream, that operates on text.
The diagram below shows how content is piped through multiple transformers between httpRequest() and createResponse() to replace "red" with "green".

Avoid bugs due to chunk boundaries and backpressureAs you can see, writing code to process data with streams is more challenging than processing buffered data.
Even in a simple example that finds and replaces text, you need to insert additional code to manage streams. Make sure you review the guidance in the Challenges with streams section to avoid introducing bugs related to chunk boundaries and backpressure.
import { ReadableStream, WritableStream } from 'streams';
import { httpRequest } from 'http-request';
import { createResponse } from 'create-response';
import { TextEncoderStream, TextDecoderStream } from 'text-encode-transform';
class FindReplaceStream {
constructor (find, replace) {
let readController = null;
// Create new ReadableStream
this.readable = new ReadableStream({
start (controller) {
// retrieve controller for ReadableStream when start() function is called
readController = controller;
}
});
// Create new WritableStream
this.writable = new WritableStream({
// write() function is called on each chunk of text
// replace content in each chunk and enqueue modified text
write (text) {
let modifiedText = text.replace(find, replace);
readController.enqueue(modifiedText);
},
// Close readable stream when writable stream is closed
close (controller) {
readController.close();
}
});
}
}
export async function responseProvider (request) {
// Make httpRequest to retrieve content
var httpResponse = await httpRequest('https://www.example.com/content.html');
// Create a response, piping through a chain of transformers
return createResponse(
httpResponse.status,
{},
httpResponse.body
.pipeThrough(new TextDecoderStream())
.pipeThrough(new FindReplaceStream('red', 'green'))
.pipeThrough(new TextEncoderStream())
);
}Challenges with streams
Once you have implemented find-replace within an EdgeWorkers function review your code and the guidance below for details about how to handle chunk boundaries and backpressure.
Chunk boundaries
You need to handle data spanning boundaries as expected. The FindReplaceStream code above performs a find and replace on each chunk of text as it flows through the EdgeWorkers function. This works correctly when the text chunks look like this.

There is, however, no method to control how chunks are split, and there is no guarantee that splits will occur in ideal locations. If you split the exact same text slightly differently, the code above will fail to find "red" in the text. All instances of "red" split across chunk boundaries and we are only searching within individual chunks.

Backpressure
In some cases, you cannot write data to a stream immediately. For example, there are inherent delays in writing data when it's sent across a network with limited bandwidth. In the FindReplaceStream example from the previous section, it's possible to read from the server faster than data can be written to the client. In this case, the transformed data cannot be discarded until it is written to the client. This enqueued data continues to consume EdgeWorkers memory until it is written or it exceeds the EdgeWorkers memory limits.
To avoid this scenario, you can use a stream to control the writing of data through backpressure. If a stream cannot currently accept more data, it can propagate a signal back through the chain, signaling upstream producers to wait before sending more data. This backpressure prevents data from piling up in the middle of the processing chain.
A full description of how to implement backpressure is out of scope of this topic. To ensure that you implement backpressure properly when transforming streams you can use the TransformStream class.
The code sample below replaces text using a TransformStream to handle backpressure properly. The code does not, however, find and provide a solution for text that spans chunk boundaries.
import { ReadableStream, WritableStream } from 'streams';
import { httpRequest } from 'http-request';
import { createResponse } from 'create-response';
import { TextEncoderStream, TextDecoderStream } from 'text-encode-transform';
class FindReplaceTransformer {
constructor (find, replace) {
this.find = find;
this.replace = replace;
}
transform(chunk, controller) {
let modifiedText = chunk.replace(this.find, this.replace);
readController.enqueue(modifiedText);
}
}
export async function responseProvider (request) {
// Make httpRequest to retrieve content
var httpResponse = await httpRequest('https://www.example.com/content.html');
// Create TransformStream object
var findReplaceTransformStream = new TransformStream(new FindReplaceTransformer('red', 'green'));
// Create a response, piping through a chain of transformers
return createResponse(
httpResponse.status,
{},
httpResponse.body
.pipeThrough(new TextDecoderStream())
.pipeThrough(findReplaceTransformStream)
.pipeThrough(new TextEncoderStream())
);
}Complete find and replace
Refer to the EdgeWorkers GitHub repo for an example of find and replace that properly handles text that spans chunk boundaries and signals backpressure. This library contains code using the built-in string functions to search within chunks. It also manually implements a string search algorithm to find text that may cross boundaries.
3. More than text and bytes
In EdgeWorkers we typically think about streams in the context of bytes and text. Streams can, however, consist of any JavaScript object. This can be useful for more advanced implementations. For example, you can add a JavaScript tag to the end of the HTML head tag, but only if the JavaScript is not already present.
To add a JavaScript tag to the end of the HTML tag.
-
Use
FindStreamto search for the tag.FindStreamtransforms the text input to an output stream. -
The output stream consists of an object that contains the original text. It also includes an annotation of the position where the string was first found in the overall stream. If the string is not yet found a value of
undefinedis applied. -
InsertUntilStreamthen reads the stream of objects and generates an output stream of text. It looks for the</head>tag and inserts the script just before the</head>tag, but only if the object from the previous transform indicates the script tag is not yet found.
If the script is not already present in the content, the flow looks like this, inserting the script just prior to the tag.

If the script is present, the FindStream locates the script and signals the InsertUntilStream script through the location property of the object passed through the stream.
Updated 3 months ago