Create a site snapshot
The Site Snapshot Tool (SST) is an advanced, robust, and flexible solution that automates the process of downloading content from an enterprise onto the Edge Platform. Create a site snapshot whenever you need to make a backup, perform failovers, import content from another vendor, or move content from one storage group to another.
When to use Site Snapshot
Site Snapshot is beneficial whenever you need to take a snapshot of your content and place it on NetStorage. Here are a few scenarios where Site Snapshot would be beneficial:
- Failover. Pull files from your origin to your failover site.
- Origin offload. Automatically keep an update-to-date copy of your site on NetStorage. Useful when NetStorage acts as the primary origin, rather than the backup origin.
- Backups. Used as a backup copy of your content.
- Automation. Any use case that requires automated ingest into NetStorage.
About the failover site
Setting up the failover site for use is a largely transparent process.
A flag is set on your normal configuration, so that if a failure occurs, the failover site content is automatically used. The failover content used as your origin is checked periodically at a configurable frequency, such as every 30 or 60 seconds. Once the origin is back online, normal service is restored.
For the end user, the switch from a failed origin to the failover site is also seamless, but there may be some latency as time-outs run, and confirmation that your origin is down is processed.
Failover and redirects
One notable difference between your origin and the failover site - the failover does not follow HTTP redirects. NetStorage will return a header containing the 406 response (Not Acceptable) for a redirect request made to the failover. To accommodate this issue, redirects must be written into your failover configuration, via Edge Configuration/ARL.data, in order to change the response that is returned to a 302.
Failover behavior is controlled by the edge delivery configuration in Property Manager, not your NetStorage configuration.
Features of Site Snapshot
- Interfaces Web-based interface in Control Center, as well as a command line interface. These provide the ability to create any number of simple or complex periodic Snapshot configurations.
- Protocol Support. HTTP and FTP are both supported with Site Snapshot.
- FTP. A “passive retrieval” option is available for FTP, which is discussed in detail later in this documentation.
- HTTP. You can specify HTTP headers, load cookies, and ignore or respect robots files.
- Supports URL Lists. Site Snapshot allows you to specify the URLs for downloads either manually or by listing in an input file (a flat text file listing URLs, one per line).
- Recursive Downloads. Site Snapshot offers the ability to set recursive behavior and the levels of such (i.e., you can set the tool to follow and download the links in the URLs to any number of levels). You can choose to download page requisites such as images and style sheet links, and you can convert links to reference the failover site.
- Additional Features. You can limit downloads to files that have changed since the previous snapshot, limit the total size of the download, set a time-out period and error logging.
Before you begin
Site Snapshot must be provisioned
SST functionality is associated with each CP code configured within a NetStorage storage group. Therefore, an individual CP code must be provisioned to allow SST access.
Access the Site Snapshot tool
You can access the interface by navigating from within Control Center:
- Go to ☰ ⇒ ORIGIN SERVICES ⇒ NetStorage
- Select the Site Snapshots entity.
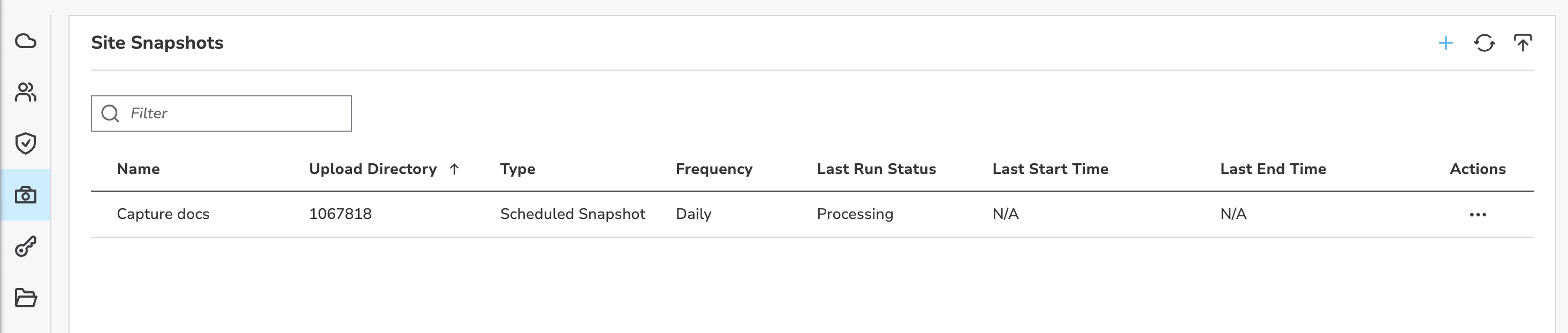
Schedule a Snapshot
Click + to access the Schedule Snapshot interface.
Basic information
- Name. Input a name for this snapshot configuration. This value is for your convenience and use in distinguishing between different snapshots.
- Directory. Input a complete path destination to save the snapshot.
- Frequency. Select the desired snapshot frequency.
Frequency options
- Create a Snapshot with no schedule. Select this option to configure a snapshot without actually running it. This allows you to save a configuration and execute it at a later time, for example, by either running a schedule now configuration, or define a Frequency.
- Daily. Select this option to define the desired time of day.
- Weekly. Select this option to choose a specific day of the week and a desired time at which a snapshot should be taken.
- Monthly. Select this option to specify a specific date in the month, and a desired time on that date at which a snapshot should be taken.
Snapshot configuration
- Custom SST command. Toggle this option to enable the ability to use the SST command field. When it's selected, the entire section in the UI is hidden.
- SST command. This field displays your current snapshot configuration. If you enable the Custom SST command, this field allows you to provide an SST command manually. Review the SST command format for a complete set of SST command options.
As options are set via other UI options, their SST command equivalent will be revealed as the SST command. The easiest way to create a new command is to copy and paste this command into the SST command field, and modify it as desired.
When using a custom override in the NetStorage UI, the commands shouldn't contain single quotes ( ' ) around URL or path variables.
Source URLs
These options allow you to specify the URL(s) from which the snapshot should perform the download.
- Take a snapshot of the specified URLs. Specify one or more URLs in this text box to serve as target(s) for the snapshot. Ensure that each URL exists on its own line in this box (for example, hit Enter after each entry to define a new URL).
- Take a snapshot of the URLs listed in a file. Input the complete path and file name (including extension) to a file comprised of URLs to include in the snapshot. The file must:
- Be a text file, in which each individual URL exists on its own line
- Already exist in the path specified (i.e., you will need to upload it to the specified directory in NetStorage prior to generating the snapshot).
Both Snapshot methods support the inclusion of FTP (ftp://example.com), and HTTP (http://www.example.com), or a combination of both can be used.
Recursive download
Site Snapshot can recursively follow HTML links.
The SST can identify and follow HTML links such as “a/href” and “img/src” from your Primary Site URL(s) and include associated content (for example, pages, images, stylesheets, etc.) in the snapshot. Choose one of the following recursion options:
Download mode options
- Only the URLs listed. Only those URLs specified as your Primary Site URLs will be included (for example, only those specific files - no associated images, stylesheets, etc. will be included in the snapshot).
- Recursively up to specified levels. Use the associated fields to define the number of levels in the link tree you want the snapshot to delve. For example, if your Primary URL links to a secondary page that links to a tertiary page, and that page links to three more pages, inputting a Level of 2 in this field would include the Primary, the secondary and the tertiary page files - the three additional pages that link off of the tertiary would not be included. Additional settings are available, when this option is selected:
- Convert Links. With a specific depth level established, this option will change links on downloaded pages to access the appropriate page within the failover site generated by the snapshot. This will maintain link integrity between all downloaded pages within the link tree. For example, without it set, clicking a link on a downloaded page will attempt to reach the target page in origin site, not within the failover, which could be met with an error if your origin site is unavailable.
- Page Requisites. Select this option to include all associated files in the snapshot. For example, images, stylesheets, etc.
- Accepted Domain List. Specify a domain accept list when using recursiveness. For multiple domains enter a comma separated list.)
- Recursively all levels. With this option selected, the snapshot will recurse all levels and include all files.
- Accepted Domain List. Use the following domain accept list when using recursiveness. For multiple domains enter a comma separated list.
Recursion limits, input files, and cookies
The SST cannot recursively find and download links embedded in JavaScript such as pop-ups or image links, and it cannot follow links that generate a pull-down menu or mouse-overs. In addition, SST does not download pages that are generated in response to a user interaction such as filling out a form field. As a workaround, you can specifically target pages accessed via these means by establishing a unique Primary Site URL for each page when generating a snapshot.
For a list of tags/attributes followed for recursion, please see the description of the sst command option, -r --recursive.
Recursion doesn't parse JavaScriptIf certain pages on your site are only accessible via a Javascript-based link or similar means, it's recommended that you include these pages individually as Primary Site URLs.
Optional settings
HTTP and FTP Options
- Header list. With this option selected, enter request headers, one per line, that will be sent from the requester (the failover site), to your origin when the files are requested.
- Cookies file. Input the complete path and file name (including extension) to a cookie file that will be passed to the HTTP server on your origin site. The file must already exist within your failover site, in the path specified (i.e., you will need to upload it to the specified directory in NetStorage prior to generating the snapshot).
- Ignore robots file. When selected, any restrictions that a robots file contains regarding what may be downloaded will be ignored.
- FTP retrieval scheme. Enabling this option may circumvent various firewall issues. At the time of publication, detailed information on Active vs. Passive FTP could be found at the following URL: http://www.slacksite.com/other/ftp.html
- Retrieve symbolic links. Enable this option to have the snapshot follow and download files linked from symbolic links.
Additional Options
- Maximum size (in bytes). Limits the total size of the snapshot, in bytes. Define a numeric value here to serve as a stopping point for the snapshot, in regards to the total size of downloaded content.
- Timeout (in seconds). Input a numeric value to serve as a stoppage point for the snapshot in regards to time. For example, if you do not want your storage group resources impacted longer than a specified amount of time. The default time-out is 900 seconds (15 minutes), it's automatically applied if a value isn't set for this option.
- Log file. Log error and other messages. Identify a complete path within your storage group to serve as a destination for generated log files. If a subdirectory is specified in the associated field, that sub-directory must already exist within your storage group, prior to initiating the snapshot.
- Preserve timestamp. This functionality allows you to perform “incremental” snapshots of your origin site, and only new or changed content will be included in each subsequent snapshot, after the first.
Summary
Review the configuration to confirm the settings. Once you are satisfied with your snapshot configuration, click the Save button. The view will revert to the Site Snapshot dashboard with the new snapshot displayed in the table.
Use the SST command to customize your snapshot
Site Snapshot uses SST commands to build a snapshot configuration.
Each individual component in the string must be separated with a white space (“ ”), and the components are as follows:
Command format: sst <command option 1> <command option 2> <URL>
- Preface each command with the
sststring. - Include the desired
<command option #>and its associated data (as applicable). Multiple command options are allowed in a single command. Separate each with a single whitespace. - Specify the complete
<URL>to the site having its “snapshot” taken.
By default, SST is default limited to 50,000 files per operation. If necessary, however, you may override this limit with the upload-quota option.
Example SST usage
Download recursively
Download www.example.com, and recurse through links to download those files as well. Download only those files that are newer than the ones already on the failover site, and do not create a host directory www.example.com/.
Example: sst -r -N -nH http://www.example.com
- Domain: www.example.com
- Option:
-r --recursive: Links within the targeted page will be followed and their associated content/pages will also be downloaded - Option:
-N --timestamping: Only include files if they are newer than any files that were previously downloaded. - Option:
-nH --no-host-directories: Do not include a hostname directory in the hierarchy.
Download based on content
Load the cookies file and download based on its contents; include page requisites, and add the noted Referrer header.
Example: sst -p --load-cookies=cookies.txt --header=“Referrer: http://www.example.com/index.jsp” http://www.example.com
- Domain: www.example.com
- Option:
-p --page-requisites: Download any other associated files that may be required to properly display the page. - Option:
--load-cookies: Load the cookies contained in a specific file. - Option:
--header: Specify a desired
Download newer files from a list
Download the files listed in clipart.txt and the page requisites needed to display the pages, but download files only if they are newer than the ones on the failover site.
Example: sst -p -N --input-file=clipart.txt
- Option:
-p --page-requisites: Download any other associated files that may be required to properly display the page. - Option:
-N --timestamping: Only include files if they are newer than any files that were previously downloaded. - Option:
--input-file: Get the list of URLs to download from a named file.
Available command options
| Command Option | Description |
|---|---|
-A --accept=<LIST> | Download only files with the extensions or patterns specified as the <LIST> variable. Separate multiple entries with a whitespace. |
-B --base=<URL> | Prepend any relative links in an input file with a specific URL (i.e., as defined for the <URL> variable). |
-D --domains=<LIST> | Follow only domains specified as the <LIST> variable. Separate multiple entries with a whitespace. |
-F --force-html | Regard an input file to be HTML. |
-g --glob=<on/off> | Enable or disable globbing to allow or disallow special wildcard characters. |
-G --ignore-tags=<LIST> | Follow all of the default HTML tags that are normally followed during recursion (see the -r -- recursive option below) except those specified as the <LIST> variable. Separate multiple entries with a whitespace. |
-h --help | Display help information |
-H --span-<hosts> | Allow recursion to move to other hosts, by providing the URLs as the<hosts> variable, separating multiple entries with a whitespace. This command must be used with the -D --domains=<UST> option. |
-i --input-file=<FILE> | Get the list of URLs to download from a named file (input the complete path and file name for this file as the <FILE> variable). |
-I --include-directories=<LIST> | Follow only directories specified as the <LIST> variable. Separate multiple entries with a whitespace. |
-k --convert-links | Change absolute hyperlinks to relative. |
-l --level=<#> | Limit recursion depth to a specific number of levels, by setting the <#> variable to the desired number. The maximum recursion depth is 10. Recursion limits apply to directory depth and following links. |
-L --relative | Follow only relative links. |
-m --mirror | Enable options necessary to perform mirroring. |
-nd --no-directories | When performing recursive downloads, do not recreate the site’s directory hierarchy structure; instead, copy all files to the working directory. |
-nH --no-host-directories | Do not include a hostname directory in the hierarchy. |
-N --timestamping | Only include files if they are newer than any files that were previously downloaded. |
-o --output-file=<FILE> | Send operation information to a specified file instead of to the standard output. Include the desired path and filename for this file as the <FILE> variable. |
-O ---output-document=<FILE> | Do not download files, but concatenate their contents and write them to a specific file. Include the desired path and filename for this file as the <FILE> variable. |
-p --page-requisites | In addition to the specified HTML page, also download any other associated files that may be required to properly display the page (for example, image files, CSS files, etc.) |
-P -- directory-prefix=<PREFIX> | Download all files and subdirectories to a directory called <PREFIX>. |
-q --quiet | Do not display the operation’s step-by-step execution. |
-Q --quota=<#> | Set a byte-count limit as the <#> variable for downloading multiple files recursively, or from an input file (suffix with k for kilobytes or m for megabytes. For example, 20m for 20 megabytes). |
-r --recursive | Include this option to perform the download recursively (for example, links within the targeted page will be followed and their associated content/pages will also be downloaded.) Depth limits:
By default, if you use recursion the following tags/attributes will be followed: a/href applet/code area/href bgsound/src body/background embed/href embed/src fig/src frame/src iframe/src img/href img/lowsrc img/src input/src layer/src link/href overlay/src script/src table/background td/background th/background base/href |
-R --reject=<LIST> | Download all files except those with the extensions or patterns specified as the <LIST> variable. Separate multiple entries with a whitespace. |
-S --server-response | Display sent HTTP server headers and FTP server responses. |
-t --tries=<#> | Perform a specified <#> of attempts to download each URL (20 is the default; and 0 - zero - can be set to make unlimited retries). |
-T --timeout=<#> | Do not allow DNS lookups, connection attempts, and/or read idle times to exceed a specific <#> of seconds. |
-v --verbose | Display the operation’s execution step by step (this is implied when using the sst command). |
-w --wait=<#> | At the end of a file retrieval, wait a specified <#> of seconds before retrieving the next file. |
-x --force-directories | Re-create the directory hierarchy, regardless of whether one normally would be created. |
-X --exclude-directories=<LIST> | Follow all directories except those specified as the <LIST> variable. Separate multiple entries with a whitespace. |
-z --convert-absolute | Change relative hyperlinks to absolute. |
--exclude-domains=<LIST> | Follow all domains except those specified as the <LIST> variable. Separate multiple entries with a whitespace. |
--follow-ftp | Do not ignore FTP links within HTML pages. |
--follow-tags=<LIST> | Follow only a subset of default HTML tags that when recursing, by specifying the desired tags as the <LIST> variable (please see the -r --recursive option above). |
--header=<STRING> | Specify a desired <STRING> to be included with HTTP requests’ headers. |
--http-user=<USER> | Specify a username as the <USER> variable for access to the HTTP server (if applicable). |
--http-passwd=<PASS> | Set the <PASS> variable to the password associated with the username defined via the — http-user=<USER> command for access to the HTTP server (if applicable). |
--ignore-robots | Do not honor the robot.txt file or the robots metatag. |
--limit-rate=<RATE> | Do not download faster than <RATE> (suffix with k for kilobytes/second or m for megabytes/second. For example, 1m for a one megabyte maximum rate). |
--load-cookies=<FILE> | Prior to the first download, load the cookies contained in a specific file (i.e., by setting the complete path and filename to the desired file as the <FILE> variable). The cookie file must follow a specific format: domain ignore path secure expires name |
--no-clobber | Do not download a file if it already exists in the working directory. |
--no-http-keep-alive | Disable the persistent connection feature. |
--no-parent | When using recursion (-r --recursive), never ascend to the starting point’s parent directory. |
--passive-ftp | Use passive mode to require the client to start communications with the server. |
--random-wait | If a file fails to download, wait either OxWAIT, IxWAIT, and 2xWAIT, determined randomly, before reattempting the download (“WAIT” is the <SECONDS> variable set with the option, -waitretry=<SECONDS>). |
--retr-symlinks | Ignore symbolic links when performing recursive download (-r --recursive), and download the link targets instead, unless the target is a directory. |
--save-cookies=<FILE> | Before quitting the session, save all of the valid cookies to a specific file (i.e., by setting the complete path and filename to the desired file as the <FILE> variable). The cookie file follows a specific format: domain ignore path secure expires name |
--spider | Check for the presence of files without actually downloading them. |
--upload-quota=<QUOTA> | Override the default 50,000 file limit for this operation only, and set the new limit to <QUOTA> (for example, --upload-quota=100000). |
--waitretry=<SECONDS> | If a file fails to download, reattempt after one (1) second; if it again fails to download, wait two seconds and try again, and so on until <SECONDS> between attempts is reached and then stop. |
Snapshot status definitions
| Status | Description | Action |
|---|---|---|
| NEW | A new snapshot has been created and placed in queue. | The snapshot will automatically run based on the configured "Frequency". You can also click "Schedule Now" to run immediately. |
| SELECTING IP | Site Snapshot is actively running. | None |
| RUNNING | Site Snapshot is actively running. | None |
| OK | Site Snapshot completed successfully. | None |
| ERROR | Site Snapshot encountered an unspecified error. | Test your configuration to view detailed information. |
| UNKNOWN | Site Snapshot encountered an unspecified error. | Test your configuration. |
| AUTH_ERROR | The user account associated with Site Snapshot does not have access. | Permissions for the associated CP code may be incorrect. Try testing your configuration manually. |
| Processing | Site Snapshot is preparing to run. | None |
| ERROR_CONFIG | This is an unsupported SST configuration. | Edit and verify your SST configuration. Try testing your configuration manually to troubleshoot. |
| DNS_FAILURE | Unable to resolve target hostname. | Retry your snapshot. If failures continue try manually testing your configuration. |
Considerations using site snapshot
Establish an appropriate snapshot frequency
The SST allows you to set a frequency at which snapshots of your origin site will be taken. It is important that you establish a reasonable frequency based on the complexity of the targeted site, and how often that site actually changes, (i.e., whether a new snapshot is actually merited). For example, a site that is targeted with a highly regular frequency (for example, daily, at a peak usage time), that is not actually updated that frequently may result in an excessive amount of files included within the NetStorage Storage Group targeted by the snapshots (and possibly exceed the size limit of the Storage Group). In addition to establishing an appropriate frequency, the SST offers additional features that can be incorporated to streamline your snapshots.
Recursion limits, input files, and cookies
The SST downloads URLs and the various files related to URLs. In a snapshot, recursion refers to following actual links — not a directory tree. SST can download the HTML and FTP symbolic links it finds within a URL, as well as the links it finds in those URLs; it can also download images and style-sheets referenced in the URLs.
The SST cannot recursively find and download links embedded in JavaScript such as pop-ups or image links, and it cannot follow links that generate a pull-down menu or mouse-overs. In addition, SST does not download pages that are generated in response to a user interaction such as filling out a form field. As a workaround, you can specifically target pages accessed via these means by establishing a unique Primary Site URL for each page when generating a snapshot.
Additional recursion conditions
- There is a recursion level limit in NetStorage. The recursion maximum for a storage group is ten levels. Recursion limits apply to directory depth and following links.
- Take caution when using this option. Depending on the complexity of the target URL, a considerable amount of content may be downloaded with this option enabled. Ensure that this will not require more space than you currently have available.
- Default recursion depth. If omitted, the default recursion depth is set to 10.
- Maximum recursion depth. 10
Know your site complexity
It is unreasonable to assume that a single configured snapshot can appropriately traverse a complex commerce property or web site. With the above points in mind, when incorporating recursion, you should:
- Plan Multiple, Complementary Snapshots. Establish separate snapshots for individual complex pages within your site. This will allow more granularity of control, and promote proper recursion in a snapshot.
- Use Multiple NetStorage Sub-directories. Generate multiple sub-directories within your target Storage Group, and send individual snapshots to a different directory. This will avoid an over-abundance of files in a single directory, allowing for better management.
You can ignore robots
SST can ignore robots - origin files meant to prevent spiders from downloading objects you do not want them to download. SST will obey the robot and potentially not download files you want, unless you tell SST to ignore it.
Multiple configurations
Using the sst command interface, “more than one configuration” simply means issuing multiple commands via the interface.
Using the SST interface in Control Center however, you can set up a number of different configurations at the same frequency. For example, you could set up three configurations that all download weekly on Sundays at 2:00 a.m.
To illustrate using pseudo-code, you might create three different commands or configurations which, taken together, download your entire site.
-- get the host www.example.com and its page requisites and links
-- get the menu objects specified in menus.txt
-- get the art and image objects needed for dynamically created pagesSnapshots take time to complete
Your initial snapshot takes longer than subsequent snapshots.
Downloading an entire site the first time can require a significant amount of time as much as a day or possibly more. Subsequent downloads can take much less time if you download only those files that have been modified since the previous download.
Therefore it is strongly recommended that you take this time requirement into consideration for your first snapshot download, and plan accordingly.
Updated 5 months ago