Set up your recovery policy
Here, you add the Origin Failure Recovery Policy behavior to a rule in your property and configure the various failure scenarios that must be met to trigger a failover.
Where can you add this behavior?
This is entirely up to you. You can apply it in the Default Rule so it applies to all requests, or include it in a separate rule with unique match criteria to suit your needs. Remember that rules lower in the list take precedence over the Default Rule. They're acted on first, but the behaviors you've set in the Default Rule are still applied because they apply to all requests.
Some caveats apply to where you can include this behavior:
-
This behavior cannot be applied in the Origin Failure Recovery Methods rule. This rule does not support behaviors. It only supports its two sub-rules and their required behaviors. You can't include this behavior in the sub-rules, either.
-
The Origin Failure Recovery Methods rule has to be the last rule in the list. This is to ensure its settings get properly applied. So, you can't include a rule after the Origin Failure Recovery Methods rule and include the Origin Failure Recovery Policy behavior in it.
1. Add the behavior
Start by adding the Origin Failure Recovery Policy behavior to the appropriate rule. Here, we're adding it to the Default Rule to have it apply to all requests.
-
Select the Default Rule in your property.
-
Click Add Behavior.
-
In the Search available behaviors field, input "Origin Failure" to filter the listed rules. Select Origin Failure Recovery Policy from the list.
-
Select On to enable it.
2. Define Tuning Parameters
These are optional settings you can apply to exclude a problematic origin for an amount of time.
| Option | Description |
|---|---|
| Enable IP Avoidance | Enable this to exclude IP addresses associated with an origin for a period of time, after a certain number of failures occur. When an IP address is excluded, requests will failover to another IP address associated with the primary origin (if applicable). Once all IP addresses associated with primary have been excluded, the Recovery Method Configuration established for Origin Responsiveness Monitoring (ORM) is applied. These points apply here:
|
| IP Avoidance Error Threshold | This is the number of failures that must occur before an origin's IP address is excluded. |
| IP Avoidance Retry Interval (seconds) | This is the amount of time that must elapse before a failed origin IP address is removed from the exclude list. |
| Binary Equivalent Content | Enable this to support and apply internal performance optimizations for binary equivalent content (BEC). To use BEC, your content must be identical, byte-for-byte between the primary and backup origin/ See Before you begin with AMD Failover for more details. |
3. Configure the failure scenarios
A failure scenario is a selection of settings you define to determine when to trigger a retry or recovery method you've set in the Origin Failure Recovery Methods rule. Multiple failure scenarios are offered, and you can configure one or all of them for use in your policy.
Origin Responsiveness Monitoring
Configure this failure scenario to continually monitor connectivity health to your primary origin and define a retry or recovery method. Enable Monitor Origin Responsiveness, which gives you access to additional configuration options:
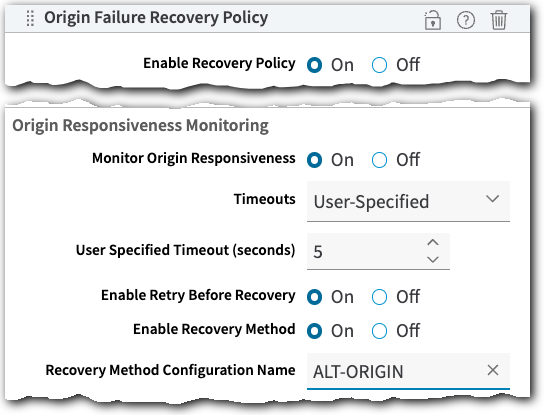
| Option | Description |
|---|---|
| Timeouts | Select the timeout threshold condition to use to trigger a retry or recovery method. You can also select User-Specified to set your own timeout, and input the desired time in User Specified Timeout (seconds). The Aggressive, Moderate, and Conservative conditions use a segment-based logic and default times. They are discussed in greater detail in Timeouts, below.
|
| Enable Retry Before Recovery | Enable this if you'd like Akamai to retry after a failure before trying the recovery method.
|
| Enable Recovery Method | Enable this to incorporate a recovery method for this failure scenario. |
| Recovery Method Configuration Name |
Timeouts
When defining Origin Responsiveness Monitoring in your Origin Failure Recovery Policy, you need to establish a Timeout configuration. Three preset values are offered—Aggressive, Moderate, or Conservative—or you can apply a User Specified Timeout in seconds.
This timeout is a threshold that's used to trigger a retry or a recovery action. For example, if the timeout was five seconds, a request to your primary origin that meets or exceeds this time would trigger the retry or recovery action.
The preset thresholds
Each of the preset thresholds has a default time for the trigger, in seconds.
| Threshold | Segment Duration |
|---|---|
| Aggressive | 2 seconds |
| Moderate | 3 seconds |
| Conservative | 4 seconds |
The User Specified threshold
This is relatively self-explanatory. Select this threshold and define the amount of time to trigger the retry or failover, in the User Specified Timeout (seconds ) field that's revealed.
Status Code Monitoring
Configure these failure scenarios to continually monitor for specific origin status codes that you specify, in order to apply a retry or recovery method.
Status Code Monitoring: Configuration 1
This is the primary configuration. To include it as your failure scenario:
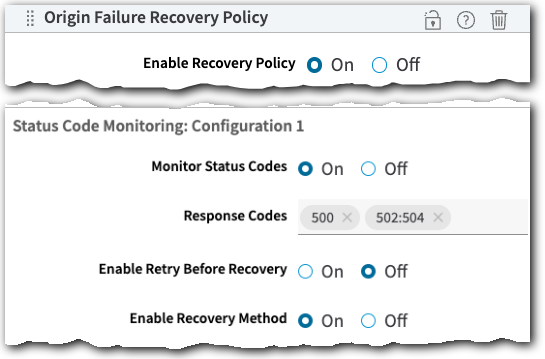
-
Enable Monitor Status Codes.
-
Set additional configuration options:
| Option | Description/Notes |
|---|---|
| Response Codes | Define the origin response codes you want to trigger this specific retry or recovery method. You can input a single code entry (501) or a range (501:504). |
| Enable Retry Before Recovery | Enable this if you'd like Akamai to retry after a failure before trying the recovery method.
|
| Recovery Method Configuration Name | Input the value you applied as the Recovery Configuration Name for the recovery method you want to use:
|
Status Code Monitoring: Configuration 2 & 3
These are additional iterations of the Status Code Monitoring: Configuration 1 failure scenario that you can implement to include different recovery methods for different origin status codes.
The setup and use of these failure scenarios are exactly the same as Status Code Monitoring: Configuration 1. However, the following apply:
- You can't use repeat origin status codes. For example, if you've added "501" as a code in Status Code Monitoring: Configuration 1, you cannot use it in Status Code Monitoring: Configuration 2 or Status Code Monitoring: Configuration 3.
Example use case: Mixed failure scenarios
This policy incorporates both failure scenarios, and it uses both of the recovery methods set in the Origin Failure Recovery Method rule. Origin responsiveness monitoring failures trigger a failover to a backup origin, and requests that result in specific HTTP error codes trigger a different error response code that's sent to the client.
This example assumes that the default configuration was used in the Origin Failure Recovery Methods—the Failure Recovery Method1 sub-rule defines a backup origin for failover, and Failure Recovery Method2 sub-rule defines a specific HTTP status code that's returned to a requesting client for failover.
Step 1: Enable and configure Origin Responsiveness Monitoring
For this use case, we want to use the recovery method to failover to a backup origin for this failure scenario. Once the failure conditions set here apply, the request fails over to the backup origin defined in Failure Recovery Method1 in the Origin Failure Recovery Method rule.
| Option | Description |
|---|---|
| Monitor Origin Responsiveness | Set this to On to enable this and access additional configuration options. |
| Timeouts | Select the timeout threshold condition to use to trigger a retry or recovery method, or select "User-Specified" to set your own timeout. Then, you need to input a desired time in the User Specified Timeout (seconds) that's revealed. The Aggressive, Moderate, and Conservative conditions use a segment-based logic and default times. They are discussed in greater detail in Timeouts section. |
| Enable Retry Before Recovery | Enable this if you'd like Akamai to retry after a failure before trying the recovery method. |
| Enable Recovery Method | Enable this to incorporate a recovery method for this failure scenario. |
| Recovery Method Configuration Name | For this use case, we'd apply the Recovery Configuration Name set in Failure Recovery Method1, because it's set up for failover to a backup origin. Using the examples from that process, apply the value "Alt-origin." |
Step 2: Enable and configure Status Code Monitoring: Configuration 1
For this use case, we want to send a different HTTP response code to the client when the request results in one of several HTTP status codes we define. Once the failure conditions set here apply, the request fails and the response code defined in Failure Recovery Method2 in the Origin Failure Recovery Method rule is sent to the client.
While there are multiple iterations of the Status Code Monitoring failure scenario, we're only using Status Code Monitoring: Configuration 1 for this use case.
| Option | Description/Notes |
|---|---|
| Monitor Status Codes | Set this to On to enable this and access additional configuration options. |
| Response Codes | Define the origin response codes you want to trigger this specific retry or recovery method. You can input a single code entry (501) or a range (501:504). Separate multiple entries with a comma (501, 503). |
| Enable Retry Before Recovery | Enable this if you'd like Akamai to retry after a failure before trying the recovery method. |
| Recovery Method Configuration Name | Input the value you applied as the Recovery Configuration Name for the applicable recovery method. For this use case, we'd apply the Recovery Configuration Name set in Failure Recovery Method2, because it's set up to deliver a specific response code to the client. Using the examples from that process, apply the value "Status-code-failover." |
Other Status Code Monitoring failure scenarios
There are additional "Status Code Monitoring: Configuration" failure scenarios in a policy. You could optionally configure another one to have it failover to the backup origin for specific origin status codes. To do so, you'd combine what's discussed in the previous two sections.
Apply the following settings in the Status Code Monitoring: Configuration 2 failure scenario:
-
Monitor Status Codes. Enabled.
-
Response Codes. Input one or more different origin status codes to trigger this failure scenario. They must be different from any you've included in Status Code Monitoring: Configuration 1.
-
Enable Retry Before Recovery. This is optional. Enable this if desired.
-
Recovery Method Configuration Name. Input the Recovery Configuration Name set in Failure Recovery Method1, because it's set up for failover to a backup origin.
Updated 5 months ago